Appearance
DDD经典分层架构
要理解DDD(领域驱动设计)的分层架构,我们需要先回到DDD的核心目标:将业务逻辑与技术细节隔离,让领域模型(即对业务的抽象表达)成为系统的核心。分层的本质是通过“职责边界划分”,避免业务逻辑被技术细节(如数据库、接口协议)侵蚀,同时让各层的变化互不影响(比如换数据库不影响领域逻辑,改接口协议不影响应用流程)。 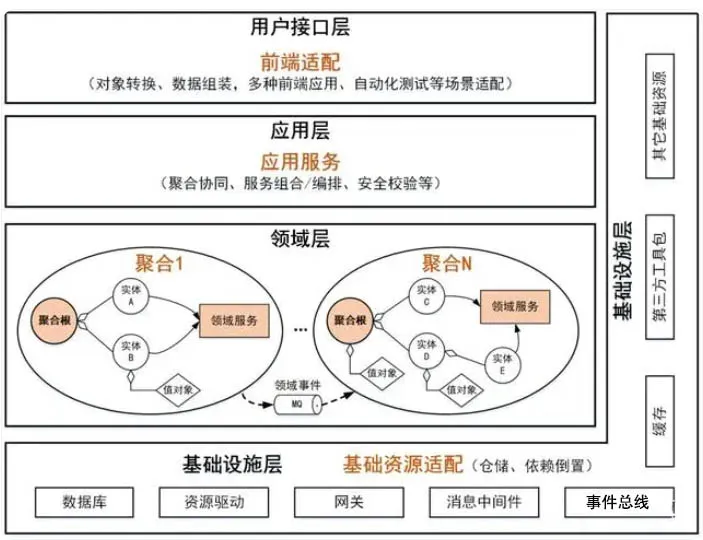
一、DDD经典分层架构的核心层次
DDD的分层架构并非固定公式,但经典四层模型(用户接口层→应用层→领域层→基础设施层)是最广泛使用的框架,我们从上层到核心依次拆解:
1. 第一层:用户接口层(User Interface Layer)——「用户与系统的“翻译官”」
核心职责:处理用户(或外部系统)的输入/输出,将用户请求转换为应用层能理解的参数,再将应用层的结果转换为用户能理解的响应(如JSON、页面、消息)。
本质:无业务逻辑,仅做“参数映射”和“渠道适配”。
常见组件:
- API接口(如Spring Boot的
@RestController)、RPC接口; - 前端页面控制器(如Thymeleaf的
@Controller); - 消息消费者(如RabbitMQ的Listener)、定时任务入口。
- API接口(如Spring Boot的
例子:
一个电商系统的“创建订单”接口:java@RestController public class OrderController { @Autowired private OrderApplicationService orderAppService; // 依赖应用层服务 @PostMapping("/orders") public ResponseEntity<OrderResponse> createOrder(@RequestBody CreateOrderRequest request) { // 1. 校验请求参数格式(如必填项、手机号格式) validateRequest(request); // 2. 转换参数:将前端的DTO转为应用层的Command(命令对象) CreateOrderCommand command = Convert.toCommand(request); // 3. 调用应用层服务执行核心流程 OrderDTO orderDTO = orderAppService.createOrder(command); // 4. 转换结果:将应用层的DTO转为前端响应 OrderResponse response = Convert.toResponse(orderDTO); return ResponseEntity.ok(response); } }关键原则:
- 绝对不做业务逻辑(如“判断用户是否有优惠券”不能放在这里);
- 只处理“渠道相关”的逻辑(如HTTP状态码、JSON序列化、消息格式);
- 依赖应用层的接口(而非具体实现),通过IoC容器注入。
2. 第二层:应用层(Application Layer)——「业务流程的“编排者”」
核心职责:协调领域对象(实体、值对象)完成具体的业务流程,不包含核心业务规则,仅负责“调用谁、按什么顺序调用”。
本质:流程胶水层,将领域层的“原子业务能力”组装成用户需要的“完整业务场景”。
常见组件:
- 应用服务(Application Service):如
OrderApplicationService、UserApplicationService; - 命令/查询对象(Command/Query):封装用户请求的参数(如
CreateOrderCommand包含商品ID、用户ID、地址); - DTO(数据传输对象):用于层间数据传递(如
OrderDTO)。
- 应用服务(Application Service):如
例子:
“创建订单”的应用层逻辑:java@Service public class OrderApplicationService { @Autowired private UserRepository userRepository; // 依赖领域层的仓储接口 @Autowired private ProductRepository productRepository; @Autowired private OrderRepository orderRepository; @Autowired private InventoryDomainService inventoryDomainService; // 依赖领域层的服务 public OrderDTO createOrder(CreateOrderCommand command) { // 1. 获取领域对象(从仓储中加载实体) User user = userRepository.findById(command.getUserId()); Product product = productRepository.findById(command.getProductId()); // 2. 调用领域服务校验业务规则(如库存是否充足) inventoryDomainService.checkStock(product.getId(), command.getQuantity()); // 3. 执行领域对象的行为(如创建订单实体) Order order = Order.create(user, product, command.getQuantity(), command.getAddress()); // 4. 调用领域事件(如订单创建后发送通知) order.publishEvent(new OrderCreatedEvent(order.getId())); // 5. 持久化领域对象(调用仓储接口) orderRepository.save(order); // 6. 转换为DTO返回 return Convert.toDTO(order); } }关键原则:
- 不写“为什么要做”(核心业务规则),只写“怎么做”(流程步骤);
- 依赖领域层的抽象(如
UserRepository接口、InventoryDomainService),而非具体实现; - 避免直接操作数据库、缓存等技术细节(这些交给基础设施层);
- 一个应用服务方法对应一个用户故事(如“创建订单”“取消订单”),保持单一职责。
3. 第三层:领域层(Domain Layer)——「系统的“大脑”,DDD的核心」
核心职责:封装核心业务规则和领域知识,是系统中最稳定、最有价值的部分(业务专家的知识都沉淀在这里)。
本质:领域模型的载体,所有与业务相关的“是什么”(实体/值对象)和“怎么做”(领域服务/事件)都在这里。
领域层的核心组件是实体(Entity)、值对象(Value Object)、领域服务(Domain Service)、领域事件(Domain Event)、仓储接口(Repository Interface),我们先拆解前四个核心组件:
(1)实体(Entity):有唯一标识的“业务对象”
定义:具有唯一身份标识(ID),且其身份不依赖属性的对象(即使属性全变,ID不变则对象不变)。
核心特征:
有
id字段(如orderId、userId);有行为(而非单纯的“数据容器”)——实体的行为体现业务规则。
例子:订单实体(
Order):javapublic class Order { // 唯一标识(实体的核心) private OrderId id; // 关联的用户(实体) private UserId userId; // 商品信息(值对象) private ProductVO product; // 数量(基本类型) private int quantity; // 订单状态(枚举,体现业务规则) private OrderStatus status; // 总金额(值对象) private Money totalAmount; // 私有构造方法(强制通过工厂方法创建,保证对象合法性) private Order() {} // 工厂方法:创建订单(封装“订单必须包含用户、商品、数量”的规则) public static Order create(User user, Product product, int quantity, Address address) { Preconditions.checkNotNull(user, "用户不能为空"); Preconditions.checkNotNull(product, "商品不能为空"); Preconditions.checkArgument(quantity > 0, "数量必须大于0"); Order order = new Order(); order.id = OrderId.generate(); order.userId = user.getId(); order.product = ProductVO.from(product); order.quantity = quantity; order.status = OrderStatus.CREATED; // 计算总金额(值对象的行为) order.totalAmount = product.getPrice().multiply(quantity); return order; } // 行为:取消订单(封装“只有未支付的订单才能取消”的规则) public void cancel() { if (this.status != OrderStatus.CREATED) { throw new BusinessException("只有未支付的订单才能取消"); } this.status = OrderStatus.CANCELED; // 发布领域事件(取消后恢复库存) this.publishEvent(new OrderCanceledEvent(this.id)); } }关键原则:
- 实体不能是“贫血模型”(即只有getter/setter,没有行为)——所有与实体相关的业务规则都要封装在实体的方法中;
- 通过工厂方法(如
create)创建实体,避免外部直接new(保证对象创建时的合法性); - 实体的
id应使用领域类型(如OrderId而非String),避免primitive obsession(基本类型偏执)。
(2)值对象(Value Object):无唯一标识的“不可变对象”
定义:没有唯一身份标识,通过属性值唯一的对象。一旦创建,属性不可修改(不可变性)。
核心特征:
无
id字段;不可变(所有属性都是
final,没有setter);Equality基于属性值(重写
equals和hashCode)。例子:金额值对象(
Money):javapublic class Money { private final BigDecimal amount; // 金额 private final Currency currency; // 币种(如人民币、美元) // 构造方法私有化,通过静态方法创建 private Money(BigDecimal amount, Currency currency) { this.amount = amount.setScale(2, RoundingMode.HALF_UP); // 强制两位小数 this.currency = currency; } // 静态工厂方法:创建Money对象 public static Money of(BigDecimal amount, Currency currency) { Preconditions.checkNotNull(amount, "金额不能为空"); Preconditions.checkArgument(amount.compareTo(BigDecimal.ZERO) >= 0, "金额不能为负"); Preconditions.checkNotNull(currency, "币种不能为空"); return new Money(amount, currency); } // 行为:金额相乘(返回新的Money对象,保持不可变性) public Money multiply(int factor) { Preconditions.checkArgument(factor > 0, "乘数必须大于0"); return Money.of(this.amount.multiply(new BigDecimal(factor)), this.currency); } // 重写equals和hashCode(基于amount和currency) @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Money money = (Money) o; return Objects.equals(amount, money.amount) && Objects.equals(currency, money.currency); } @Override public int hashCode() { return Objects.hash(amount, currency); } }关键原则:
- 用值对象代替基本类型(如用
Money代替BigDecimal+String(币种)),避免“魔法值”和逻辑分散; - 不可变性:值对象一旦创建,属性不能修改(避免并发问题和意外修改);
- 适合封装“无身份、靠属性唯一”的概念(如金额、地址、颜色、时间范围)。
- 用值对象代替基本类型(如用
(3)领域服务(Domain Service):跨实体的业务规则
定义:当业务规则需要多个实体协作,或不适合放在任何实体/值对象中时,将其封装为领域服务。
核心特征:
无状态(不保存数据,只处理业务逻辑);
方法名体现业务动作(如
checkStock、calculateDiscount)。例子:库存领域服务(
InventoryDomainService):java@Service public class InventoryDomainService { @Autowired private ProductRepository productRepository; @Autowired private InventoryRepository inventoryRepository; // 校验库存(需要商品实体和库存实体协作) public void checkStock(ProductId productId, int quantity) { Product product = productRepository.findById(productId); Inventory inventory = inventoryRepository.findByProductId(productId); if (inventory.getStock() < quantity) { throw new BusinessException("商品" + product.getName() + "库存不足,当前库存:" + inventory.getStock()); } } }关键原则:
- 领域服务不是“工具类”:工具类是通用的(如
DateUtils),而领域服务是业务相关的(如“校验库存”是电商领域的核心规则); - 领域服务只依赖领域层的组件(如实体、值对象、仓储接口),不依赖应用层或基础设施层;
- 避免滥用:能放在实体/值对象中的逻辑,绝对不放在领域服务中(比如“计算订单总金额”应该放在
Order实体中,而不是领域服务)。
- 领域服务不是“工具类”:工具类是通用的(如
(4)领域事件(Domain Event):领域内的“重要事实”
定义:领域内发生的对业务有影响的事件(如“订单创建成功”“库存不足”),用于解耦领域对象之间的依赖(通过事件通知而非直接调用)。
核心特征:
命名体现“已发生的事实”(如
OrderCreatedEvent、StockInsufficientEvent);包含事件的关键信息(如订单ID、发生时间)。
例子:订单创建事件(
OrderCreatedEvent):javapublic class OrderCreatedEvent { private final OrderId orderId; private final LocalDateTime occurredAt; public OrderCreatedEvent(OrderId orderId) { this.orderId = orderId; this.occurredAt = LocalDateTime.now(); } // getter方法(无setter,保持不可变性) public OrderId getOrderId() { return orderId; } public LocalDateTime getOccurredAt() { return occurredAt; } }使用场景:
- 订单创建后,通知库存系统减库存(
OrderCreatedEvent→库存服务监听并执行reduceStock); - 订单支付成功后,通知积分系统加积分(
OrderPaidEvent→积分服务监听并执行addPoints)。
- 订单创建后,通知库存系统减库存(
关键原则:
- 领域事件由领域对象发布(如
Order实体的create方法发布OrderCreatedEvent); - 事件处理者异步执行(避免同步调用导致的性能问题和耦合);
- 事件是不可变的(一旦发布,不能修改)。
- 领域事件由领域对象发布(如
(5)仓储接口(Repository Interface)
在DDD中,仓储(Repository)是领域层的核心组件之一,它的作用是封装领域对象的持久化细节,让领域层不用关心“数据存在哪里”“怎么存”,只需要通过仓储的抽象接口操作领域对象。
(5.1)仓储的核心职责
- 存储:将领域对象(如
Order、User)保存到持久化介质(数据库、缓存等); - 获取:根据领域条件(而非技术条件)查询领域对象(如“根据订单ID获取订单”“查询用户的未支付订单”);
- 聚合根边界:仓储仅针对**聚合根(Aggregate Root)**设计(聚合根是领域模型的“大颗粒”对象,包含多个实体和值对象,比如
Order是聚合根,包含OrderItem实体)。
(5.2)为什么仓储接口属于领域层?
仓储的定义(即“需要哪些存储/查询方法”)是领域知识的一部分。比如“订单仓储需要支持根据用户ID查询未支付订单”是业务需求,而非技术需求,因此仓储接口必须放在领域层,由业务专家参与设计。
而仓储的实现(比如用MySQL存订单、用Redis缓存用户)是技术细节,属于基础设施层(后面会讲)。
(5.3)示例:订单仓储接口
java
// 领域层的仓储接口(属于领域层)
public interface OrderRepository {
// 保存订单(聚合根)
void save(Order order);
// 根据订单ID获取订单
Order findById(OrderId orderId);
// 根据用户ID查询未支付的订单(领域术语,无技术细节)
List<Order> findUnpaidOrdersByUserId(UserId userId);
}(5.4)关键原则
- 仓储接口只暴露领域相关的方法:避免用
findByCreateTimeBetween这样的技术查询条件(这是数据库的细节),而要用findRecentCreatedOrders(最近创建的订单)这样的领域术语; - 仓储仅操作聚合根:比如不能直接保存
OrderItem(订单条目),必须通过Order聚合根保存(保证聚合内的一致性); - 仓储无业务逻辑:只做“存/取”,不做“校验库存”“计算金额”这样的业务规则。
4. 第四层:基础设施层(Infrastructure Layer)——「技术细节的“实现者”」
核心职责:实现领域层的抽象(如仓储接口、领域服务的依赖),提供通用的技术服务(数据库、缓存、消息队列、文件存储等),是系统的“地基”。
简单来说,基础设施层是“做脏活累活的”:所有与技术相关的细节都在这里实现,上层(应用层、领域层)不需要关心。
(1)常见组件
- 仓储实现:如
OrderRepositoryImpl(实现领域层的OrderRepository接口,用JPA/MyBatis访问MySQL); - 技术服务:数据库连接池(HikariCP)、缓存客户端(RedisTemplate)、消息队列客户端(RabbitMQListener)、文件存储(MinIO);
- 工具类:通用的技术工具(如
JsonUtils、DateUtils); - 领域事件实现:如用RabbitMQ实现领域事件的发布/订阅(
OrderCreatedEvent的生产者/消费者)。
(2)示例:订单仓储的实现
java
// 基础设施层的仓储实现(依赖领域层的接口)
@Repository
public class OrderRepositoryImpl implements OrderRepository {
// 依赖JPA的Repository(技术细节)
@Autowired
private JpaOrderRepository jpaOrderRepository;
// 依赖转换器(将领域对象转为JPA实体)
@Autowired
private OrderConverter orderConverter;
@Override
public void save(Order order) {
// 将领域对象(Order)转为JPA实体(JpaOrder)
JpaOrder jpaOrder = orderConverter.toJpaEntity(order);
// 调用JPA保存(技术细节)
jpaOrderRepository.save(jpaOrder);
}
@Override
public Order findById(OrderId orderId) {
// 调用JPA查询
Optional<JpaOrder> jpaOrder = jpaOrderRepository.findById(orderId.getValue());
// 将JPA实体转为领域对象
return jpaOrder.map(orderConverter::toDomainEntity).orElse(null);
}
@Override
public List<Order> findUnpaidOrdersByUserId(UserId userId) {
// 调用JPA查询(技术细节:根据user_id和status查询)
List<JpaOrder> jpaOrders = jpaOrderRepository.findByUserIdAndStatus(userId.getValue(), OrderStatus.CREATED);
// 转为领域对象列表
return jpaOrders.stream().map(orderConverter::toDomainEntity).collect(Collectors.toList());
}
}
// JPA的Repository(纯技术细节,属于基础设施层)
public interface JpaOrderRepository extends JpaRepository<JpaOrder, String> {
List<JpaOrder> findByUserIdAndStatus(String userId, OrderStatus status);
}(3)关键原则
- 依赖领域层的抽象:基础设施层的实现类必须依赖领域层的接口(如
OrderRepositoryImpl实现OrderRepository),而非上层依赖基础设施层的实现; - 隐藏技术细节:上层(应用层、领域层)看不到数据库、缓存的存在,所有技术细节都被封装在基础设施层;
- 可替换性:如果需要换数据库(比如从MySQL到PostgreSQL),只需要修改基础设施层的
OrderRepositoryImpl,上层代码完全不变。
三、DDD分层架构的核心约束:依赖规则(Dependency Rule)
DDD分层架构的灵魂是依赖倒置原则(DIP),即:
上层只能依赖下层的抽象(接口),不能依赖下层的具体实现;下层不能依赖上层。
用“依赖箭头”表示各层的关系:
用户接口层 ← 应用层 ← 领域层 → 基础设施层
(注:“←”表示“依赖于”,即应用层依赖领域层的抽象,基础设施层依赖领域层的抽象)
(1)具体约束细节
- 用户接口层:只能依赖应用层的接口(如
OrderApplicationService),不能依赖领域层或基础设施层; - 应用层:只能依赖领域层的抽象(如
UserRepository、InventoryDomainService),不能依赖基础设施层的实现; - 领域层:不依赖任何上层(用户接口层、应用层),也不依赖基础设施层的具体实现;
- 基础设施层:可以依赖领域层的抽象(如实现
OrderRepository),但不能依赖上层(应用层、用户接口层)。
(2)为什么要遵守依赖规则?
- 解耦:上层不依赖下层的具体实现,修改下层(如换数据库)不会影响上层;
- 可测试性:上层可以用Mock替换下层的实现(如用
MockOrderRepository测试OrderApplicationService); - 业务聚焦:领域层不会被技术细节侵蚀,始终保持“纯业务”的核心地位。
四、DDD分层架构的实践误区
很多团队学DDD时,容易陷入以下误区,导致分层失去意义:
1. 贫血领域模型(Anemic Domain Model)
症状:实体(如Order)只有getter/setter,没有任何行为,所有业务逻辑都放在应用层(如OrderApplicationService)。
危害:领域模型失去了“封装业务规则”的作用,变成了“数据容器”,业务逻辑分散在应用层,难以维护。
反例:
java
// 错误:贫血的Order实体(只有getter/setter)
public class Order {
private String id;
private String userId;
private int quantity;
private OrderStatus status;
// 只有getter/setter,没有行为
}
// 错误:应用层做了领域层的事(判断订单是否可取消)
@Service
public class OrderApplicationService {
public void cancelOrder(String orderId) {
Order order = orderRepository.findById(orderId);
// 业务规则放在应用层(应该放在Order实体的cancel方法里)
if (order.getStatus() != OrderStatus.CREATED) {
throw new BusinessException("不能取消已支付的订单");
}
order.setStatus(OrderStatus.CANCELED);
orderRepository.save(order);
}
}正确做法:将业务规则封装在实体的行为中(如Order.cancel()方法),应用层只调用实体的行为。
2. 仓储接口泄漏技术细节
症状:领域层的Repository接口暴露了数据库的查询条件(如findByCreateTimeBetween)。
危害:领域层被技术细节污染,换数据库时需要修改领域层代码。
反例:
java
// 错误:仓储接口暴露数据库细节(between是SQL的关键字)
public interface OrderRepository {
List<Order> findByCreateTimeBetween(LocalDateTime start, LocalDateTime end);
}正确做法:用领域术语代替技术条件:
java
// 正确:用领域术语(最近7天创建的订单)
public interface OrderRepository {
List<Order> findOrdersCreatedInLast7Days();
}3. 应用层承担领域职责
症状:应用层处理核心业务规则(如“计算订单折扣”“校验用户权限”)。
危害:应用层变成“业务逻辑大杂烩”,领域层失去核心地位。
正确做法:核心业务规则必须放在领域层(实体、值对象、领域服务),应用层只做流程编排。
4. 依赖倒置未落地
症状:应用层直接依赖基础设施层的实现(如@Autowired OrderRepositoryImpl),而非领域层的接口。
危害:换数据库时需要修改应用层代码,违反开闭原则。
正确做法:应用层依赖领域层的接口(如@Autowired OrderRepository),通过IoC容器注入实现类。
五、DDD分层架构的优势
DDD分层架构的所有设计,都是为了解决**复杂业务系统的“可维护性”和“扩展性”**问题,具体优势如下:
1. 业务与技术分离
领域层沉淀了纯业务知识(业务专家能直接看懂),技术细节被封装在基础设施层,避免“业务逻辑被技术代码淹没”。
2. 高内聚、低耦合
各层职责明确:
- user接口层:只处理输入输出;
- 应用层:只做流程编排;
- 领域层:只做业务规则;
- 基础设施层:只做技术实现。
修改某一层的代码,不会影响其他层(如换前端框架不影响领域逻辑,换数据库不影响应用流程)。
3. 可测试性强
- 领域层的组件(实体、值对象、领域服务)可以单独测试(不需要启动数据库或服务器);
- 应用层可以用Mock替换领域层的实现(如用
MockOrderRepository测试OrderApplicationService); - 基础设施层的实现可以单独测试(如测试
OrderRepositoryImpl是否正确保存订单)。
4. 应对业务变化
当业务需求变化时(如“新增优惠券抵扣规则”),只需要修改领域层的Order实体或CouponDomainService,应用层和用户接口层不需要修改;当技术需求变化时(如“从MySQL换成PostgreSQL”),只需要修改基础设施层的OrderRepositoryImpl,上层完全不变。
5. 团队协作高效
- 业务团队(产品、业务专家)专注于领域层的设计;
- 技术团队(后端、前端)专注于各层的实现;
- 分层明确后,团队分工更清晰,避免“互相干扰”。
六、总结:DDD分层架构的本质
DDD分层架构不是“银弹”,但它是复杂业务系统的“设计方法论”——通过分层将“业务核心”与“技术细节”隔离,让系统的稳定性(核心业务规则不变)和灵活性(技术细节可替换)达到平衡。
最后用一句话总结DDD分层的核心:
领域层是“大脑”,决定“做什么”;应用层是“手脚”,决定“怎么做”;用户接口层是“眼睛和嘴巴”,负责“和外界沟通”;基础设施层是“身体”,负责“提供能量和支持”。