Appearance
Hystrix 高频面试题
Hystrix 作为 Netflix 开源的分布式系统容错框架,曾是 Spring Cloud 生态中解决「雪崩效应」的核心组件。即使目前被 Resilience4j 等框架替代,其设计思想(隔离、熔断、降级)仍是分布式系统容错的基础,因此仍是面试中的高频考点。 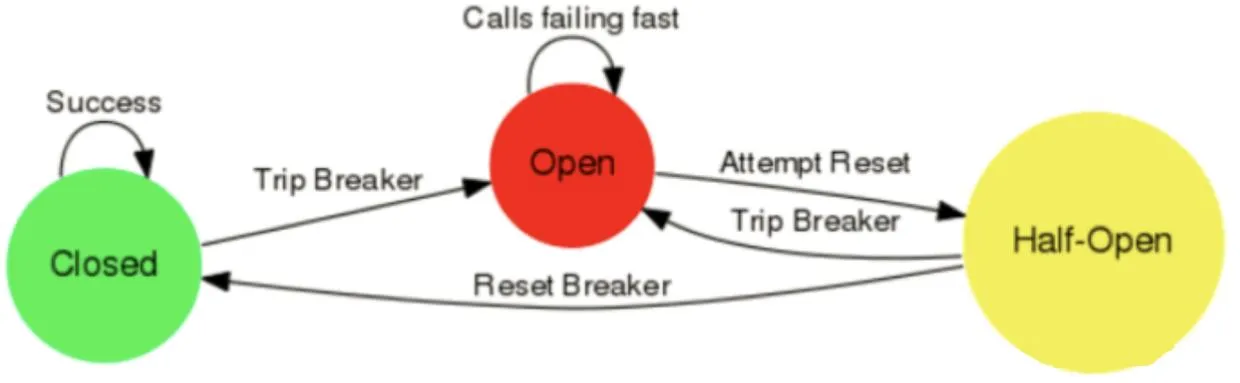
一、基础概念类问题
1. 什么是 Hystrix?它解决了分布式系统中的什么问题?
- 定义:Hystrix 是一个延迟和容错库,用于隔离分布式服务之间的依赖,防止单个服务故障导致整个系统雪崩。
- 解决的核心问题:雪崩效应(Avalanche Effect)—— 当分布式链路中的某一个服务(如 B 服务)故障(超时、宕机),上游服务(如 A 服务)的请求会阻塞等待 B 服务响应,导致 A 服务的线程池耗尽,最终整个链路崩溃。
- Hystrix 的解决方案:通过服务隔离(线程池/信号量)、熔断(快速失败)、降级(返回兜底结果)三大机制,将故障限制在局部,避免扩散。
2. Hystrix 的核心设计原则有哪些?
Hystrix 的设计完全围绕「容错」展开,核心原则包括:
- 服务隔离:将每个依赖服务的调用封装在独立的线程池/信号量中,避免单个依赖的故障耗尽主服务的资源。
- 熔断机制:当依赖的失败率超过阈值时,主动切断请求(断路器打开),快速返回 fallback 结果,避免无效重试。
- 降级策略:当依赖调用失败、超时或线程池满时,执行备用逻辑(如返回默认值、缓存数据),保证服务可用性。
- 实时监控:收集每个依赖的 metrics(请求成功率、延迟、失败率),用于断路器的状态决策和系统监控(Hystrix Dashboard/Turbine)。
- 请求优化:通过请求缓存(同一上下文内重复请求直接返回缓存结果)和请求合并(批量处理高并发的重复请求)减少依赖调用次数。
二、核心组件与工作流程
3. Hystrix 的核心组件有哪些?各自的作用?
Hystrix 的核心组件围绕 HystrixCommand(封装依赖调用)展开,主要包括:
- HystrixCommand/HystrixObservableCommand:
封装对依赖服务的调用逻辑。HystrixCommand用于返回单个结果的同步/异步调用(如execute()同步、queue()异步);HystrixObservableCommand用于返回多个结果的响应式调用(如observe()实时订阅、toObservable()延迟订阅)。 - Circuit Breaker(断路器):
控制依赖的请求流量,有三种状态:- Closed(关闭):正常转发请求,记录失败率;
- Open(打开):失败率超过阈值(默认 50%)且请求数超过最小阈值(默认 20),切断请求,直接走 fallback;
- Half-Open(半开):打开状态持续一段时间(默认 5 秒)后,允许少量请求尝试调用依赖,若成功则关闭断路器,否则回到打开状态。
- ThreadPool(线程池隔离):
为每个依赖分配独立的线程池,避免单个依赖的慢调用耗尽主服务线程。核心参数包括coreSize(核心线程数,默认 10)、maxQueueSize(队列大小,默认 -1 即同步队列)。 - Fallback(降级逻辑):
依赖调用失败时执行的备用逻辑,需保证简洁(不依赖外部服务),避免二次故障。 - Metrics( metrics 收集):
收集每个HystrixCommand的执行数据(成功/失败/超时/拒绝次数、延迟等),用于断路器的状态判断和监控。
4. Hystrix 的完整工作流程是怎样的?
Hystrix 的执行流程可分为 11 步,是面试的高频考点,需理解每一步的逻辑:
- 构造 Command:创建
HystrixCommand或HystrixObservableCommand,封装依赖调用。 - 执行 Command:调用
execute()(同步)、queue()(异步)、observe()(响应式)等方法触发执行。 - 检查请求缓存:若开启缓存(重写
getCacheKey()),且缓存存在,则直接返回缓存结果(跳过后续步骤)。 - 检查断路器状态:
- 若断路器打开:直接执行 fallback(步骤 10);
- 若关闭/半开:继续下一步。
- 检查线程池/信号量:
- 若线程池满(或信号量耗尽):执行 fallback(步骤 10);
- 否则:分配线程执行依赖调用。
- 执行 run()/construct():
HystrixCommand执行run()方法(同步调用依赖);HystrixObservableCommand执行construct()方法(响应式调用依赖)。
- 记录 Metrics:将执行结果(成功/失败/超时/拒绝)记录到 metrics 中。
- 更新断路器状态:根据 metrics 判断是否需要切换断路器状态(如失败率超过阈值则打开断路器)。
- 返回成功结果:若
run()/construct()执行成功,返回结果(结束流程)。 - 执行 Fallback:若步骤 4/5/6 失败,执行 fallback 逻辑(若 fallback 也失败,抛出异常)。
- 返回最终结果:返回 fallback 结果或异常。
三、核心机制深度解析
5. Hystrix 的服务隔离有哪两种方式?区别与适用场景?
Hystrix 支持线程池隔离和信号量隔离,两者的核心差异在于「是否使用独立线程」:
| 维度 | 线程池隔离 | 信号量隔离 |
|---|---|---|
| 原理 | 为每个依赖分配独立线程池,请求在独立线程中执行 | 使用计数器控制并发数,请求在主线程中执行 |
| 隔离强度 | 强隔离(线程级),故障不会扩散到主线程 | 弱隔离(计数器级),故障会阻塞主线程 |
| 性能开销 | 线程上下文切换开销大(约 1ms/次) | 无线程切换,开销极小 |
| 适用场景 | IO 密集型依赖(如远程调用、数据库查询) | CPU 密集型依赖(如本地计算、缓存查询) |
| 配置参数 | execution.isolation.strategy=THREAD | execution.isolation.strategy=SEMAPHORE |
| 并发控制 | 线程池大小(coreSize) | 信号量大小(semaphore.maxConcurrentRequests) |
示例:
- 调用远程服务(如订单服务):用线程池隔离,避免远程服务超时阻塞主服务线程;
- 查询本地缓存(如 Redis):用信号量隔离,因为缓存查询快,无需线程切换。
6. Hystrix 的熔断机制是如何工作的?核心参数有哪些?
熔断的本质是「快速失败」,避免无效请求占用资源。核心逻辑依赖三个参数:
- requestVolumeThreshold:最小请求数(默认 20)—— 只有当 10 秒内的请求数超过该值,才会计算失败率。
例:若 10 秒内只有 10 个请求,即使全部失败,断路器也不会打开。 - errorThresholdPercentage:失败率阈值(默认 50%)—— 当失败率超过该值,断路器从「关闭」切换到「打开」。
- sleepWindowInMilliseconds:打开状态持续时间(默认 5000ms)—— 断路器打开后,经过该时间会进入「半开」状态,允许少量请求尝试调用依赖。
状态切换流程:Closed →(失败率超阈值)→ Open →(等待 sleepWindow)→ Half-Open →(请求成功)→ ClosedHalf-Open →(请求失败)→ Open
7. 降级(Fallback)与熔断(Circuit Breaker)的区别?
| 维度 | 降级 | 熔断 |
|---|---|---|
| 触发条件 | 依赖调用失败、超时、线程池/信号量满 | 依赖失败率超过阈值 |
| 作用 | 返回兜底结果,保证服务可用性 | 切断请求,避免无效重试 |
| 关系 | 熔断是触发降级的原因之一 | 降级是熔断后的处理逻辑 |
| 主动性 | 被动(依赖故障后触发) | 主动(根据 metrics 主动切断) |
示例:
- 当线程池满了(触发降级):返回默认用户信息;
- 当依赖失败率达 60%(触发熔断):直接返回默认用户信息(降级逻辑)。
8. Hystrix 的请求缓存与请求合并有什么用?
(1)请求缓存(Request Caching)
- 作用:同一请求上下文(
HystrixRequestContext)内,相同cacheKey的请求直接返回缓存结果,减少依赖调用次数。 - 实现:需重写
HystrixCommand的getCacheKey()方法,返回唯一 key(如方法参数的组合);并在请求开始前初始化HystrixRequestContext(如通过 Filter)。 - 注意:缓存仅在当前请求上下文有效(如 HTTP 请求生命周期内),且只缓存成功结果。
示例:
java
public class GetUserCommand extends HystrixCommand<User> {
private Long userId;
public GetUserCommand(Long userId) {
super(HystrixCommandGroupKey.Factory.asKey("UserGroup"));
this.userId = userId;
}
@Override
protected User run() {
return userService.getUserById(userId); // 调用依赖
}
@Override
public String getCacheKey() {
return String.valueOf(userId); // 用 userId 作为缓存 key
}
}
// 初始化请求上下文(Filter)
public class HystrixRequestContextFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try {
chain.doFilter(request, response);
} finally {
context.shutdown();
}
}
}(2)请求合并(Request Collapsing)
- 作用:将短时间内(默认 10ms)的多个相同请求合并成一个批量请求,减少对依赖服务的调用次数。
- 实现:通过
HystrixCollapser实现,需重写getBatchRequest()(将单个请求转化为批量请求)和mapResponseToRequests()(将批量响应映射回单个请求)。 - 适用场景:高并发下的重复请求(如多个线程查询同一用户信息),且依赖服务支持批量接口(如
getUsersByIds(List<Long> ids))。
示例:
java
public class GetUserCollapser extends HystrixCollapser<List<User>, User, Long> {
private Long userId;
public GetUserCollapser(Long userId) {
super(HystrixCollapserGroupKey.Factory.asKey("UserCollapserGroup"));
this.userId = userId;
}
@Override
public Long getRequestArgument() {
return userId; // 每个请求的参数(userId)
}
@Override
protected HystrixCommand<List<User>> createCommand(List<Long> userIds) {
return new BatchGetUserCommand(userIds); // 批量请求 Command
}
@Override
protected void mapResponseToRequests(List<User> batchResponse, List<CollapsedRequest<User, Long>> collapsedRequests) {
// 将批量响应映射到每个请求
int index = 0;
for (CollapsedRequest<User, Long> request : collapsedRequests) {
request.setResponse(batchResponse.get(index++));
}
}
}
// 批量请求 Command
public class BatchGetUserCommand extends HystrixCommand<List<User>> {
private List<Long> userIds;
public BatchGetUserCommand(List<Long> userIds) {
super(HystrixCommandGroupKey.Factory.asKey("UserGroup"));
this.userIds = userIds;
}
@Override
protected List<User> run() {
return userService.getUsersByIds(userIds); // 调用批量接口
}
}四、Spring Cloud 整合与实践
9. Spring Cloud 中如何使用 Hystrix?
Spring Cloud 通过 spring-cloud-starter-netflix-hystrix 整合 Hystrix,核心步骤:
- 引入依赖:xml
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency> - 开启 Hystrix:在启动类上加
@EnableHystrix或@EnableCircuitBreaker(更通用,支持其他断路器实现)。 - 定义降级方法:用
@HystrixCommand注解标记需要容错的方法,并指定fallbackMethod(降级方法需与原方法签名一致)。 - 配置参数:通过
application.yml或@HystrixProperty配置 Hystrix 参数(如超时时间、断路器阈值)。
示例:
java
@Service
public class UserService {
@Autowired
private RestTemplate restTemplate;
// 配置 Hystrix 命令:超时时间 2s,失败率阈值 50%,最小请求数 10
@HystrixCommand(
fallbackMethod = "fallbackGetUser",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "2000"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"),
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10")
}
)
public User getUserById(Long id) {
// 调用远程服务(通过 RestTemplate 负载均衡)
return restTemplate.getForObject("http://USER-SERVICE/users/{id}", User.class, id);
}
// 降级方法:返回默认用户
public User fallbackGetUser(Long id) {
return new User(id, "默认用户", "默认地址");
}
}
// 启动类
@SpringBootApplication
@EnableHystrix
@EnableDiscoveryClient
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
// 配置 RestTemplate 负载均衡
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}10. Hystrix 线程池配置的优化技巧
线程池的配置直接影响 Hystrix 的性能,需根据QPS和响应时间计算合理参数:
- 核心线程数(coreSize):
coreSize = QPS * 平均响应时间(秒)。
例:若 QPS=100,平均响应时间=0.1s,则 coreSize=1000.1=10。* - 队列大小(maxQueueSize):
- 若依赖响应时间稳定:
maxQueueSize = coreSize * 平均响应时间 * 2(预留缓冲); - 若依赖响应时间不稳定:建议设置为
-1(同步队列,超过 coreSize 的请求直接拒绝,避免队列积压导致延迟增加)。
- 若依赖响应时间稳定:
- 队列拒绝阈值(queueSizeRejectionThreshold):即使队列没满,超过该阈值的请求也会被拒绝(默认 5),用于提前熔断。
示例配置(application.yml):
yaml
hystrix:
command:
default: # 默认全局配置,可替换为具体 commandKey
execution:
isolation:
thread:
timeoutInMilliseconds: 2000 # 超时时间
coreSize: 10 # 核心线程数
strategy: THREAD # 线程池隔离
circuitBreaker:
errorThresholdPercentage: 50 # 失败率阈值
requestVolumeThreshold: 10 # 最小请求数
sleepWindowInMilliseconds: 5000 # 打开状态持续时间
threadPool:
default: # 线程池配置
coreSize: 10
maxQueueSize: -1 # 同步队列
queueSizeRejectionThreshold: 5五、进阶与对比
12. 实际项目中使用 Hystrix 遇到的问题及解决方案?
问题 1:线程池满导致大量请求被拒绝
- 现象:监控到
threadPool.rejected指标升高,fallback 执行次数激增。 - 原因:线程池 coreSize 过小,或依赖响应时间过长导致线程占用。
- 解决方案:
- 优化依赖服务的响应时间(如加缓存、优化 SQL);
- 调整线程池 coreSize(根据 QPS 和响应时间计算);
- 若依赖响应时间不稳定,将
maxQueueSize设为-1(同步队列),避免队列积压。
问题 2:断路器误触发(短暂抖动导致打开)
- 现象:依赖服务短暂超时(如网络波动),导致断路器打开,正常请求被拒绝。
- 原因:
requestVolumeThreshold过小(默认 20),或errorThresholdPercentage过低(默认 50%)。 - 解决方案:
- 增大
requestVolumeThreshold(如调整为 50),减少小流量下的误判; - 适当降低
errorThresholdPercentage(如调整为 60%); - 增大
sleepWindowInMilliseconds(如调整为 10 秒),给依赖服务更多恢复时间。
- 增大
问题 3:fallback 逻辑执行失败
- 现象:依赖调用失败后,fallback 方法抛出异常,导致连锁故障。
- 原因:fallback 逻辑依赖外部服务(如另一个远程调用),或逻辑复杂。
- 解决方案:
- fallback 逻辑需无依赖(如返回静态默认值、内存缓存);
- 若必须依赖外部服务,对 fallback 方法也做 Hystrix 容错(不建议,会增加复杂度);
- 捕获 fallback 中的异常,返回更友好的结果。
六、总结
Hystrix 的核心是**「将故障隔离在局部,保证系统整体可用性」**,其设计思想(隔离、熔断、降级)是分布式系统容错的基础。面试时需重点掌握:
- 雪崩效应的成因与 Hystrix 的解决方案;
- 核心组件(Command、断路器、线程池)的作用;
- 服务隔离、熔断、降级的区别与实现;
- Spring Cloud 整合 Hystrix 的实践;
即使 Hystrix 已停止维护,其思想仍值得深入学习,因为这些思想是所有容错框架的底层逻辑。